我们现在将支持向量机推广到回归问题,同时保持它的稀疏性。在简单的线性回归模型中,我们最小化一个正则化的误差函数
为了得到稀疏解,二次误差函数被替换为一个-不敏感误差函数(-insensitive error function)(Vapnik, 1995)。如果预测和目标之间的差的绝对值小于,那么这个误差函数给出的误差等于零,其中。-不敏感误差函数的一个简单的例子是
它在不敏感区域之外,会有一个与误差相关联的线性代价。如图7.6所示。
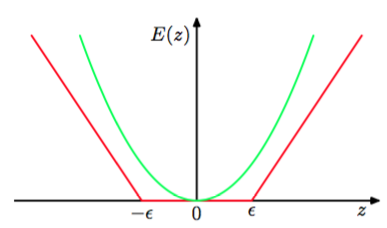
图 7.6 -不敏感误差函数(红色)在不敏感区域之外,误差函数值随着距离线性增大。作为对比,同时给出了二次误差函数(绿色)。
于是我们最小化正则化的误差函数,形式为
其中由式(7.1)给出。按照惯例,(起着相反作用的)正则化参数被记作,出现在误差项之前。
与之前一样,通过引入松弛变量的方式,我们可以重新表达最优化问题。对于每个数据点,我们现在需要两个松弛变量和,其中对应于的数据点,对应于的数据点,如图7.7所示。
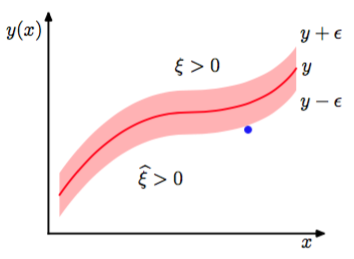
图 7.7 SVM回归的说明。图中画出了回归曲线以及-不敏感“管道”。同时给出的是松弛变量和的例子。对于-管道上方的点,且,对于-管道下方的点,且,对于-管道内部的点。
目标点位于-管道内的条件是,其中。引入松弛变量使得数据点能够位于管道之外,只要松弛变量不为零即可。对应的条件变为
这样,支持向量回归的误差函数就可以写成
它必须在限制条件和和式(7.53),(7.54)下进行最小化。通过引入拉格朗日乘数以及,然后最优化拉格朗日函数
我们现在使用式(7.1)替换,然后令拉格朗日函数关于和的导数为0,得到:
使用这些结果消去拉格朗日函数中对应的变量,我们看到对偶问题涉及到关于和最大化
其中我们已经引入了核。与之前一样,这是一个具有限制条件的最大化问题。为了找到限制条件,我们注意到,因为是拉格朗日乘数,所以它们要满足和必须成立。且和以及式(7.59)(7.60)要求且,因此我们又一次得到盒限制
以及条件(7.58)。
将式(7.57)代入式(7.1),我们看到对于新的输入变量,可以使用
进行预测,这又一次被表示为核函数的形式。
对应的Karush-Kuhn-Tucker(KKT)条件说明了在解的位置,对偶变量与限制的乘积必须等于0,形式为
根据这些条件,我们能得到一些有用的结果。首先,我们注意到如果,那么系数只能非零,这表明数据点要么位于-管道的上边界上(),要么位于上边界的上方()。类似地,的非零值表示,这些点必须位于-管道的下边界上或下边界的下方。
此外,由于将两式相加,注意到和是非负的,而是严格为正的,因此对于每个数据点或至少一个为0,或都为0。所以和这两个限制是不兼容的。
支持向量是对于由式(7.64)给出的预测有贡献的数据点,换句话说,就是那些使得或成立的数据点。这些数据点位于-管道边界上或者管道外部。管道内部的所有点都有。我们又一次得到一个稀疏解,在预测模型(7.64)中唯一必须计算的项就是涉及到支持向量的项。
参数可以通过,考虑一个数据点,满足。根据式(7.67),一定有,根据式(7.65),一定有。使用式(7.1),然后求解得到。这时我们有
其中我们使用了式(7.57)。通过考虑一个满足的数据点,我们可以得到一个类似的结果。在实际应用中,更好的做法是对所有的这些b的估计进行平均。
与分类问题的情形相同,有另一种用于回归的SVM的形式。这种形式的SVM中,控制复杂度的参数有一个更加直观的意义(Scholkopf et al., 2000)。特别地,我们不固定不敏感区域的宽度,而是固定位于管道外部的数据点的比例。这涉及到最大化
限制条件为
可以证明至多有个数据点落在不敏感管道外部,而至少有个数据点是支持向量,因此位于管道上或者管道外部。
图7.8说明了使用支持向量机解决回归问题的一个例子,数据集使用的是正弦曲线数据集。
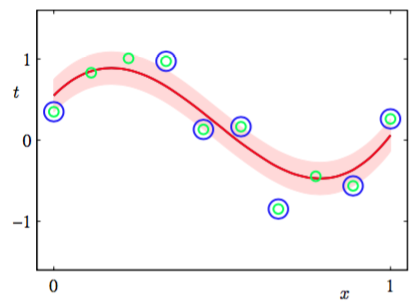
图 7.8 -SVM回归应用到人工生成的正弦数据集上的说明,SVM使用了高斯核。预测分布曲线为红色曲线,-不敏感管道对应于阴影区域。此外,数据点用绿色表示,支持向量用蓝色圆圈标记。
这里参数和已经手动选择完毕。在实际应用中,它们的值通常通过交叉验证的方法确定。