最大似然估计提供了一个估计参数的框架。现在我们通过引入这些参数的先验分布,来介绍贝叶斯方法。让我们以单元随机高斯变量这个简单的例子作为开始。假设方差已知,考虑从个观测量中推断出均值的任务。对于给定的观测到数据的概率的似然函数是关于的函数,为:
再一次强调似然函数不是关于的概率分布,也不是标准化的。
我们看到似然函数的指数以的二次型的形式出现。这意味着,如果我们选择高斯先验,那么它会是似然函数的共轭分布。因为对应的后验是两个的二次函数的指数的乘积,因此也是一个高斯分布。先令我们的先验分布为:
且后验分布由:
给出。 通过简单的配出指数中二次项的操作,可以得到的后验分布为:
其中
其中是的最大似然解,由样本均值给出:
花一点时间来学习后验均值和方差的形式是有价值的。首先,我们注意到由式(2.141)给出的后验分布的均值位于先验均值与最大似然解之间。如果观测到的数据点,那么式(2.141)像预期一样退化到先验均值。当时,后验分布由最大似然解给出。同样的,考虑式(2.142)给出的后验分布的方差。我们看到用方差的逆也就是精度来表示会更加自然。此外,精度是可加的,所以后验的精度是先验精度加上每个观测到的数据点对精度贡献。当观测到更多的数据,精度稳定的增加,对应的后验分布的方差稳定的减少。当没有观测到数据时,我们得到先验方差。当数据量时,方差趋向与0,同时后验分布在最大似然解附近变成无限高的尖峰。因此式(2.143)给出的的最大似然的点估计可以通过贝叶斯在观测数量趋于无穷时恢复精度。注意,即使对于有限的,当即先验有无限的方差,那么式(2.141)的后验均值退化成最大似然解,而式(2.142)的后验方差由给出。
图2.12展示了高斯分布均值的贝叶斯推断的分析。可以很直接地把这个结果推广到已知方差未知均值的维高斯随机变量的情况。
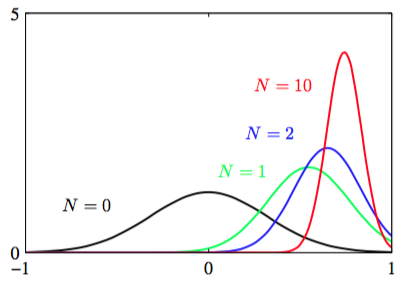
图 2.12 高斯分布的均值的贝叶斯推断
我们已经看到最大似然如何构造在观测到第个数据之后,更新之前个数据点得到的均值表达式的顺序方法。实际上,对于推断问题来说,贝叶斯范式很自然的引出顺序观点。为了证明这点,让我们来讨论一下高斯分布下的均值推断,把后验分布中最后一个数据点的贡献单独写出来:
方括号中的项(忽略标准化系数)是观测到个数据点之后的后验概率分布。把它看成一个先验分布,然后使用贝叶斯定理与和相关的似然函数结合到了一起,得到了观测到个数据点之后的后验概率。这种贝叶斯推断的顺序观点是非常通用的,可以应用于任何独立同分布的观测数据问题中。
之前,我们假设高斯分布的数据的方差是已知的,目标是推断出均值。现在假设均值是已知的,希望推断出方差。同样的,如果选择先验分布的共轭形式,我们的计算会得到大量简化。使用精度进行计算是最方便的。关于的似然函数为:
因此,对应的共轭先验正比于的幂次数和的线性函数的指数。这就是Gamma分布,定义为:
其中,是(1.141)中定义的gamma函数,同时保证了式(2.146)被正确的标准化。如果那么gamma分布积分是有穷的,如果,那么分布本身是有穷的。图2.13展示了不同的的情况下分布。

图 2.13 gamma分布
Gamma分布的均值和方差为:
考虑先验分布。如果乘以似然函数(2.145),那么就得到后验分布:
我们可以把它当作形式为的gamma分布,其中:
其中是对方差的最大似然估计。注意,在式(2.149)中不需要一直关注先验分布和似然函数的标准化常数,因为如果需要,可以使用式(2.146)给出的Gamma分布的表达式求出正确的系数。
从式(2.150)得到观测到个数据点的效果是使增加了。因此我们可以把先验分布中的参数看成个“有效”先验观测。同样的,从式(2.151)中得到个数据点为参数贡献了其中是方差,所以把先验中的参数解释为从个“有效”的先验观测的方差为。回忆一下,我们在Dirichlet先验中做过类似的解释。这些分布是指数族的例子,我们将会看到,把共轭先验解释为有效的虚拟数据点是指数族分布的一种通用方法。
在使用方差本身而不是精度的情况下,共轭先验被称为逆Gamma(inverse gamma)分布。我们不会详细地讨论这个分布,因为使用精度来进行计算会更加方便。
现在,假设均值和精度都是未知的。为了找到共轭先验,考虑似然函数对的依赖:
现在,我们在想找到一个对于的依赖与似然函数有着相同的函数形式的先验分布因此,采用形式:
其中是常量。由于总有,我们可以通过观察找到。特别的,当是一个精度为关于的线性函数的高斯分布,是一个gamma分布时,得到的标准化的先验形式为:
其中,我们的新常数为。式(2.154)的分布被称为正态-gamma(normal-gamma)或高斯-gamma(Gaussian-gamma)分布,并在图2.14中展示。
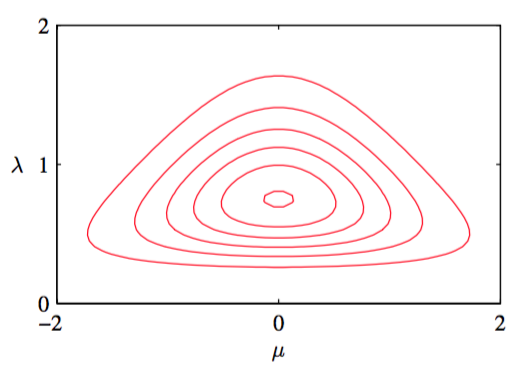
图 2.14 高斯-gamma分布
注意,因为的精度是的线性函数,所以不能简单的把一个独立的上的的高斯先验与一个上的的Gamma分布相乘。即使选择一个 相互独立的先验,后验分布中的精度和的值也会相互耦合。
对于维向量的多元高斯分布,假设精度已知,那么均值共轭先验还是高斯分布。对于已知的均值,未知的精度矩阵,共轭先验是Wishart分布:
其中是分布的自由度,是的伸缩矩阵,记作迹。标准化常量为:
同样的,用协方差矩阵本身(而不是精度)定义的先验分布也可行的,这会推导出逆Wishart分布,但是我们不会详细讨论这一点。如果均值和精度同时未知,那么,和一元变量类似的推理得到共轭先验:
这被称为正态-Wishart分布或高斯-Wishart分布。